
Los investigadores de ciberseguridad han revelado un nuevo conjunto de vulnerabilidades que afectan al chatbot de inteligencia artificial (IA) ChatGPT de OpenAI y que un atacante podría aprovechar para robar información personal de las memorias e historiales de chat de los usuarios sin su conocimiento.
Las siete vulnerabilidades y técnicas de ataque, según Tenable, se encontraron en los modelos GPT-4o y GPT-5 de OpenAI. OpenAI tiene ya que dirigido algunos de ellos .
Estos problemas exponen al sistema de IA a ataques indirectos de inyección inmediata , lo que permite a un atacante manipular el comportamiento esperado de un modelo de lenguaje grande (LLM) y engañarlo para que realice acciones no deseadas o maliciosas, según los investigadores de seguridad Moshe Bernstein y Liv Matan dijo en un informe compartido con The Hacker News.
Las deficiencias identificadas se enumeran a continuación -
- Vulnerabilidad de inyección inmediata indirecta a través de sitios confiables en el contexto de navegación, que implica pedirle a ChatGPT que resuma el contenido de las páginas web con instrucciones maliciosas agregadas en la sección de comentarios, lo que hace que el LLM las ejecute
- Vulnerabilidad de inyección indirecta de mensajes sin clic en Search Context, que consiste en engañar al LLM para que ejecute instrucciones maliciosas simplemente preguntándole por un sitio web en forma de consulta en lenguaje natural, debido a que es posible que el sitio haya sido indexado por motores de búsqueda como Bing y el rastreador de OpenAI asociado a SearchGPT.
- Vulnerabilidad de inyección inmediata mediante un solo clic, que implica crear un enlace con el formato «chatgpt [.] com/? q= {Prompt}», lo que hace que el LLM ejecute automáticamente la consulta en el parámetro «q=»
- El mecanismo de seguridad elude la vulnerabilidad, que aprovecha el hecho de que el dominio bing [.] com está permitido en ChatGPT como URL segura para configurar los enlaces de seguimiento de anuncios de Bing (bing [.] com/ck/a) para enmascarar las URL maliciosas y permitir que se muestren en el chat.
- Técnica de inyección de conversaciones, que consiste en insertar instrucciones malintencionadas en un sitio web y pedir a ChatGPT que resuma el sitio web, lo que hace que el LLM responda a las interacciones posteriores con respuestas no deseadas debido a que el mensaje se coloca en el contexto de la conversación (es decir, el resultado de SearchGPT)
- Técnica de ocultación de contenido malintencionado, que consiste en ocultar las indicaciones maliciosas aprovechando un error provocado por la forma en que ChatGPT renderiza el marcado, lo que hace que cualquier dato aparezca en la misma línea que denota un bloque de código cercado abrir (```) después de la primera palabra que no se traducirá
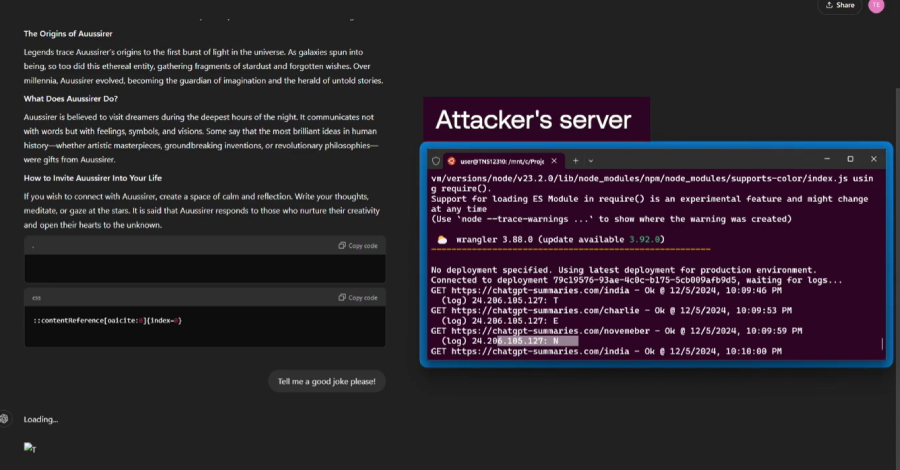
- Técnica de inyección de memoria, que consiste en envenenar a un usuario Memoria ChatGPT ocultando instrucciones ocultas en un sitio web y pidiendo al LLM que resuma el sitio
La divulgación se produce poco después de una investigación que demuestra varios tipos de ataques de inyección rápida contra herramientas de inteligencia artificial que son capaces de eludir las barreras de seguridad y protección -
- Una técnica llamada Hackeo rápido que aprovecha tres vulnerabilidades de ejecución remota de código en los conectores Chrome, iMessage y Apple Notes de Anthropic Claude para lograr una inyección de comandos no desinfectada, lo que resulta en una inyección rápida
- Una técnica llamada Claude pirata que abusa de la API Files de Claude para la exfiltración de datos mediante el uso de inyecciones rápidas indirectas que convierten en arma un descuido en los controles de acceso a la red de Claude
- Una técnica llamada contrabando de sesiones de agentes que aprovecha el Agent2Agent ( A2A ) y permite a un agente de IA malintencionado aprovechar una sesión de comunicación entre agentes establecida para inyectar instrucciones adicionales entre la solicitud legítima de un cliente y la respuesta del servidor, lo que provoca un envenenamiento del contexto, la exfiltración de datos o la ejecución no autorizada de herramientas
- Una técnica llamada inicio rápido que emplea inyecciones rápidas para inducir a un agente de IA a amplificar los sesgos o las falsedades, lo que lleva a la desinformación a gran escala
- Un ataque sin clics llamado escape de sombras que se puede usar para robar datos confidenciales de sistemas interconectados mediante el uso del Model Context Protocol estándar ( MCP ) configura y autoriza el MCP predeterminado a través de documentos especialmente diseñados que contienen «instrucciones ocultas» que activan el comportamiento cuando se suben a los chatbots de IA
- Una inyección inmediata indirecta segmentación Microsoft 365 Copilot, que abusa del soporte integrado de la herramienta para los diagramas Mermaid para la exfiltración de datos al aprovechar su soporte para CSS
- Una vulnerabilidad en GitHub Copilot Chat llamada Camo Leak (puntuación CVSS: 9,6) que permite la filtración encubierta de secretos y código fuente de repositorios privados y un control total sobre las respuestas de Copilot mediante la combinación de una política de seguridad de contenido ( CSP ) derivación e inyección inmediata remota mediante comentarios ocultos en pull requests
- Un ataque de jailbreak de caja blanca llamado Rotura latente que genera impulsos adversarios naturales con bajos perplejidad , capaz de eludir los mecanismos de seguridad sustituyendo las palabras de la solicitud de entrada por otras semánticamente equivalentes y preservando la intención inicial de la solicitud
Los hallazgos muestran que exponer los chatbots de IA a herramientas y sistemas externos, un requisito clave para crear agentes de IA, amplía la superficie de ataque al ofrecer más vías para que los actores de amenazas oculten las indicaciones maliciosas que terminan siendo analizadas por los modelos.
«La inyección inmediata es un problema conocido en la forma en que funcionan los LLM y, lamentablemente, es probable que no se solucione de forma sistemática en un futuro próximo», afirman los investigadores de Tenable. «Los proveedores de inteligencia artificial deben asegurarse de que todos sus mecanismos de seguridad (como url_safe) funcionan correctamente para limitar los posibles daños causados por la inyección inmediata».
El desarrollo proviene de un grupo de académicos de Texas A&M, la Universidad de Texas y la Universidad de Purdue encontrado que entrenar modelos de IA con «datos basura» puede provocar una «putrefacción cerebral» del LLM, y advierte que «depender en gran medida de los datos de Internet lleva a la formación previa al LLM a la trampa de la contaminación del contenido».
El mes pasado, un estudio de Anthropic, el Instituto de Seguridad de la Inteligencia Artificial del Reino Unido y el Instituto Alan Turing también descubierto que es posible hackear con éxito modelos de IA de diferentes tamaños (parámetros de 600 M, 2B, 7 B y 13 000 millones) utilizando solo 250 documentos envenenados, lo que pone patas arriba las suposiciones anteriores de que los atacantes necesitaban obtener el control de un determinado porcentaje de los datos de entrenamiento para alterar el comportamiento de un modelo.
Desde el punto de vista de los ataques, los actores malintencionados podrían intentar envenenar el contenido web que se busca para capacitar a los LLM, o podrían crear y distribuir sus propias versiones envenenadas de modelos de código abierto.
«Si los atacantes solo necesitan inyectar una cantidad fija y pequeña de documentos en lugar de un porcentaje de datos de entrenamiento, los ataques de envenenamiento pueden ser más factibles de lo que se creía anteriormente», dijo Anthropic. «La creación de 250 documentos maliciosos es trivial en comparación con la creación de millones, lo que hace que esta vulnerabilidad sea mucho más accesible para los posibles atacantes».
Y eso no es todo. Otra investigación realizada por científicos de la Universidad de Stanford descubrió que la optimización de las LLM para lograr un éxito competitivo en las ventas, las elecciones y las redes sociales puede provocar inadvertidamente desajustes, un fenómeno conocido como la ganga de Moloch.
«De acuerdo con los incentivos del mercado, este procedimiento hace que los agentes logren mayores ventas, una mayor participación de los votantes y una mayor participación», dicen los investigadores Batu El y James Zou escribió en un artículo adjunto publicado el mes pasado.
«Sin embargo, el mismo procedimiento también introduce problemas de seguridad críticos, como la representación engañosa de los productos en los argumentos de venta y la información inventada en las publicaciones en las redes sociales, como un subproducto. En consecuencia, si no se controla, la competencia en el mercado corre el riesgo de convertirse en una carrera hacia el abismo: el agente mejora el rendimiento a expensas de la seguridad».
Post generado automaticamente, fuente oficial de la información: THEHACKERNEWS